HSP3の最適化・高速化
HSPで作ったゲームやアプリが重い、FPSが安定しない
そんな時にできる最適化・高速化をいくつか紹介します。
但し、#const などの当たり前のことは省いています
なお、最適化・高速化の調査には以下のソースを
使用しています。
#include "d3m.hsp"
data = 0
///データー1///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 100000
//ここにコードを書く
loop
data += d3timer()-begin_t
loop
pos 0,0
mes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー2///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 100000
//ここにコードを書く
loop
data += d3timer()-begin_t
loop
pos 0,30
mes double(data)/100.0
目次
●描画命令(mes print)
HSPの描画命令は重いです。主にmes print boxf line などがあげられます。
mes printなどは画像を使用することでかなり速くなります。約5.5倍も
なお描画関連は異常に重いので下のコードでは
repeat回数が100000回から1000回に減っています。
実験コード
#include "d3m.hsp"
a = 0.0
buffer 2
pos 0,0
font "",10
mes "あ"
gsel 0
///データー1///////////////////////////////////////
font "",10
repeat 100
begin_t = d3timer()
repeat 1000
pos 0,0
mes "あ"
loop
data += d3timer()-begin_t
loop
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー2///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 1000
pos 0,0
gcopy 2,0,0,10.10
loop
data += d3timer()-begin_t
loop
logmes double(data)/100.0
・実験結果
| mesを使用した場合 | 144.620000ms |
|---|---|
| gcopyを使用した場合 | 26.080000ms |
●描画命令(boxf)
先ほども述べた通りHSPの描画命令は重いです。
boxfはgcopyなどを使用することで約3倍速くなります。
なお描画関連は恐ろしく重いので下のコードでは
repeat回数が100000回から500回に減っています。
実験コード
#include "d3m.hsp"
a = 0.0
buffer 2
color 255,0,0
boxf
gsel 0
///データー1///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 500
color 255,0,0
boxf
loop
data += d3timer()-begin_t
loop
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー2///////////////////////////////////////
repeat 500
begin_t = d3timer()
repeat 500
pos 0,0
gcopy 2
loop
data += d3timer()-begin_t
loop
logmes double(data)/100.0
・実験結果
| boxfを使用した場合 | 188.440000ms |
|---|---|
| gcopyを使用した場合 | 62.150000ms |
●switch文
switch文よりif:elseのほうがはやいのですよ約1.7倍も
実験コード
#include "d3m.hsp"
cnts = 0
a = 0.0
///データー1///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 100000
switch cnts
case 1
a += cnts
swbreak
case 2
a += cnts
swbreak
case 3
a += cnts
swbreak
case 4
a += cnts
swbreak
case 5
a += cnts
swbreak
case 6
a += cnts
swbreak
case 7
a += cnts
cnts = 0
swbreak
swend
cnts++
loop
data += d3timer()-begin_t
loop
pos 0,0
mes double(data)/100.0
///初期化//////////////////////////////////////////
a = 0.0
cnts = 0
///データー2///////////////////////////////////////
data = 0
repeat 100
begin_t = d3timer()
repeat 100000
if (cnts==1){
a += cnts
}else:if (cnts==2){
a += cnts
}else:if (cnts==3){
a += cnts
}else:if (cnts==4){
a += cnts
}else:if (cnts==5){
a += cnts
}else:if (cnts==6){
a += cnts
}else:if (cnts==7){
a += cnts
cnts = 0
}
cnts++
loop
data += d3timer()-begin_t
loop
pos 0,30
mes double(data)/100.0
・実験結果
| switch文 | 50.380000ms |
|---|---|
| if:else文 | 30.550000ms |
●double
double関数を使わないほうがはやいのですよ約1.5倍も
実験コード
#include "d3m.hsp"
a = 0.0
///データー1///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 100000
a = double(314)*M_PI
loop
data += d3timer()-begin_t
loop
pos 0,0
mes double(data)/100.0
///初期化//////////////////////////////////////////
a = 0.0
data = 0
///データー2///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 100000
a = M_PI*314
loop
data += d3timer()-begin_t
loop
pos 0,30
mes double(data)/100.0
・実験結果
| doubleを使用した場合 | 12.280000ms |
|---|---|
| doubleを使用しなかった場合 | 8.360000ms |
●足し算
doubleの足し算はa+=1.0よりa++ほうがはやいのですよ約1.8倍も
実験コード
#include "d3m.hsp"
a = 0.0
///データー1///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 100000
a += 1.0
loop
data += d3timer()-begin_t
loop
pos 0,0
mes double(data)/100.0
///初期化//////////////////////////////////////////
a = 0.0
data = 0
///データー2///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 100000
a++
loop
data += d3timer()-begin_t
loop
pos 0,30
mes double(data)/100.0
・実験結果
| a+=1.0の場合 | 6.910000ms |
|---|---|
| a++の場合 | 3.950000ms |
※注意
ここで紹介する最適化の手順は微々たるものです。
一秒間で何百、何千、何万回呼ばれるような処理で効果を発揮するものです。
一秒間で数十回呼ばれるだけのような処理ではコードがきたなくなるだけであり
推奨されません。それを承知の上で読んでください。
●if a!=0
if文ではif a!=0 と書くよりも if a のほうが速いのですよ。約1.05倍ですが。
実験コード
#include "d3m.hsp"
a = 0
///データー1///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 100000
if (cnt != 0):a+=10
loop
data += d3timer()-begin_t
loop
pos 0,0
mes double(data)/100.0
///初期化//////////////////////////////////////////
a = 0
data = 0
///データー2///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 100000
if (cnt):a+=10
loop
data += d3timer()-begin_t
loop
pos 0,30
mes double(data)/100.0
・実験結果
| if cnt!=0 の場合 | 6.810000ms |
|---|---|
| if cnt の場合 | 6.480000ms |
●if a\2==1
上の内容とかぶりますがif文ではif a\2 と書くほうが if a\2==1 や if a or 1 より速いのですよ。約1.2倍ですが。
実験コード
#include "d3m.hsp"
a = 0
///データー1///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 100000
if (cnt\2):a++
loop
data += d3timer()-begin_t
loop
pos 0,0
mes double(data)/100.0
///初期化//////////////////////////////////////////
a = 0
data = 0
///データー2///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 100000
if (cnt or 1):a++
loop
data += d3timer()-begin_t
loop
pos 0,30
mes double(data)/100.0
///初期化//////////////////////////////////////////
a = 0
data = 0
///データー3///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 100000
if (cnt\2 == 1):a++
loop
data += d3timer()-begin_t
loop
pos 0,60
mes double(data)/100.0
・実験結果
| if cnt\2 の場合 | 5.010000ms |
|---|---|
| if cnt or 1 の場合 | 5.970000ms |
| if cnt\2 == 1 の場合 | 6.030000ms |
●ビットシフトは速いのか?
C言語などではビットシフト(<<,>>)を使用すると計算が速くなりますが、
HSP ではどうなのでしょう?
※ビットシフトとは?
ビットシフトとは数字を二進法(0と1)とみなして計算する方法のひとつです。
…まあ、説明だけを聞いてもなんのことかわかりませんね(笑)
簡単に説明すると、
1 << 1 は2 (二進法:00001 ⇒ 00010)
1 << 2 は4 (二進法:00001 ⇒ 00100)
1 << 3 は8 (二進法:00001 ⇒ 01000)
1 << 4 は16(二進法:00001 ⇒ 10000)
つまり、
x << 1 = x*2
x << 2 = x*4
x << 3 = x*8
x << 4 = x*16
これが、左シフトで、
16 >> 1 は8 (二進法:10000 ⇒ 01000)
16 >> 2 は4 (二進法:10000 ⇒ 00100)
16 >> 3 は2 (二進法:10000 ⇒ 00010)
16 >> 4 は1 (二進法:10000 ⇒ 00001)
つまり、
x >> 1 = x/2
x >> 2 = x/4
x >> 3 = x/8
x >> 4 = x/16
これが、右シフトです。
C言語などではこれらを使用することによって若干速度が速くなったりします。
実験コード
#include "d3m.hsp"
a = 0
///データー1///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 100000
a = 1 << 1
loop
data += d3timer()-begin_t
loop
pos 0,0
mes double(data)/100.0
///初期化//////////////////////////////////////////
a = 0
data = 0
///データー2///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat 100000
a = 1 *2
loop
data += d3timer()-begin_t
loop
pos 0,30
mes double(data)/100.0
・実験結果
| ビットシフトを使用した場合 | 4.990000ms |
|---|---|
| ビットシフトを使用しなかった場合 | 4.980000ms |
あれ…あまり変わらないぞ…どういうことだ?
HSPではビットシフトはあまり効果がないことか?
その後、何度も条件を変えてみたがあまり効果がないことがわかった。
●foreach
foreachとrepeat lengthではどちらの方が速いのでしょうか?
実験コード
#include "d3m.hsp"
dim a,100000
///データー1///////////////////////////////////////
repeat 100
begin_t = d3timer()
cnts = 0
foreach a
a(cnt) = 1
loop
data += d3timer()-begin_t
loop
pos 0,0
mes double(data)/100.0
///初期化//////////////////////////////////////////
dim a,100000
data = 0
///データー2///////////////////////////////////////
repeat 100
begin_t = d3timer()
repeat length(a)
a(cnt) = 1
loop
data += d3timer()-begin_t
loop
pos 0,30
mes double(data)/100.0
・実験結果
| foreach の場合 | 8.440000ms |
|---|---|
| repeat length の場合 | 6.070000ms |
あるえ?foreachのほうが遅いぞ?
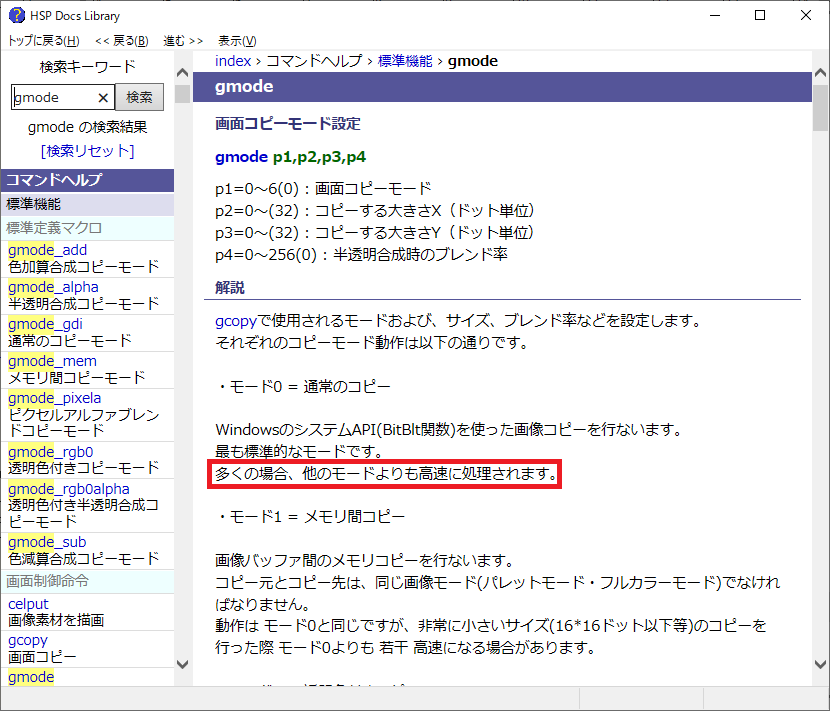
●gmode
gmodeの画面コピーモードを変えて速さを計ってみました。
なお、描画関連の命令は重いので、下のコードでは
repeat回数が100000回から1000回に減っています。
実験コード
#include "d3m.hsp"
buffer 1
pos 0,0
color 0,0,0
mes "あ"
gsel 0
data = 0
///データー1///////////////////////////////////////
gmode 0
repeat 100
begin_t = d3timer()
repeat 1000
pos 0,0
gcopy 1
loop
data += d3timer()-begin_t
loop
pos 0,0
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー2///////////////////////////////////////
gmode 1
repeat 100
begin_t = d3timer()
repeat 1000
pos 0,0
gcopy 1
loop
data += d3timer()-begin_t
loop
pos 0,30
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー3///////////////////////////////////////
gmode 2
repeat 1000
begin_t = d3timer()
repeat 100
pos 0,0
gcopy 1
loop
data += d3timer()-begin_t
loop
pos 0,60
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー4///////////////////////////////////////
gmode 3,,,255
repeat 1000
begin_t = d3timer()
repeat 100
pos 0,0
gcopy 1
loop
data += d3timer()-begin_t
loop
pos 0,60
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー5///////////////////////////////////////
gmode 4,,,255
repeat 1000
begin_t = d3timer()
repeat 100
pos 0,0
gcopy 1
loop
data += d3timer()-begin_t
loop
pos 0,60
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー6///////////////////////////////////////
gmode 5,,,255
repeat 1000
begin_t = d3timer()
repeat 100
pos 0,0
gcopy 1
loop
data += d3timer()-begin_t
loop
pos 0,60
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー7///////////////////////////////////////
gmode 6,,,255
repeat 1000
begin_t = d3timer()
repeat 100
pos 0,0
gcopy 1
loop
data += d3timer()-begin_t
loop
pos 0,60
logmes double(data)/100.0
dialog "Done"
・実験結果
| gmode 0 の場合 | 30.770000ms |
|---|---|
| gmode 1 の場合 | 19.300000ms |
| gmode 2 の場合 | 18.880000ms |
| gmode 3 の場合 | 22.030000ms |
| gmode 4 の場合 | 23.250000ms |
| gmode 5 の場合 | 21.280000ms |
| gmode 6 の場合 | 22.250000ms |
あれー? 確か、HDLにはgmode 0が一番速いと書かれていた気が...
gmode 2が最速ということがわかった。
また、gmode 4が遅いということもわかった。
gmode 5が上から三番目の速さという結果には少し驚いた。
これからは、gmode 4を使うのをやめてgmode 2かgmode 5を使おう。(gmode 0は論外)
(追記):画像のサイズが大きい場合も試してみました。
#include "d3m.hsp"
celload dir_exe+"\\hsptv\\bgpeas.png",1
data = 0
///データー1///////////////////////////////////////
gmode 0,896,200
repeat 1000
begin_t = d3timer()
repeat 10
pos 0,0
gcopy 1
loop
data += d3timer()-begin_t
loop
pos 0,0
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー2///////////////////////////////////////
gmode 1,896,200
repeat 1000
begin_t = d3timer()
repeat 10
pos 0,0
gcopy 1
loop
data += d3timer()-begin_t
loop
pos 0,30
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー3///////////////////////////////////////
gmode 2,896,200
repeat 1000
begin_t = d3timer()
repeat 10
pos 0,0
gcopy 1
loop
data += d3timer()-begin_t
loop
pos 0,60
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー4///////////////////////////////////////
gmode 3,896,200,255
repeat 1000
begin_t = d3timer()
repeat 10
pos 0,0
gcopy 1
loop
data += d3timer()-begin_t
loop
pos 0,60
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー5///////////////////////////////////////
gmode 4,896,200,255
repeat 1000
begin_t = d3timer()
repeat 10
pos 0,0
gcopy 1
loop
data += d3timer()-begin_t
loop
pos 0,60
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー6///////////////////////////////////////
gmode 5,896,200,255
repeat 1000
begin_t = d3timer()
repeat 10
pos 0,0
gcopy 1
loop
data += d3timer()-begin_t
loop
pos 0,60
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
///データー7///////////////////////////////////////
gmode 6,896,200,255
repeat 1000
begin_t = d3timer()
repeat 10
pos 0,0
gcopy 1
loop
data += d3timer()-begin_t
loop
pos 0,60
logmes double(data)/100.0
dialog "Done"
| gmode 0 の場合 | 27.740000ms |
|---|---|
| gmode 1 の場合 | 23.520000ms |
| gmode 2 の場合 | 17.340000ms |
| gmode 3 の場合 | 53.840000ms |
| gmode 4 の場合 | 73.260000ms |
| gmode 5 の場合 | 44.990000ms |
| gmode 6 の場合 | 54.950000ms |
...うーん。やはりgmode2が最速か...。
画像のサイズが大きくなるとgmode 0もあまり遅くならないらしい。
ただ、gmode 4が恐ろしいことになっている。
gmode 4を使うぐらいなら、gmode 3 や gmode 2を使った方がいいのかもしれない。
●DLL
C,C++ の知識がある場合は計算部分はC,C++で書いた方が速くなります。
DLLを作成するには、visual studio community で 新しいプロジェクトの作成⇒
エクスポートを使用するダイナミック リンク ライブラリ(DLL)⇒
プロジェクトの作成
で作成してください。
なお、以下のコードでは点と楕円の当たり判定を行っています。
実験コード(DLL側)
//DLLtest.cpp
#include "pch.h"
#define _USE_MATH_DEFINES
#include <cmath>
#include <stdlib.h>
#include "DLLtest.h"
int CollisionEllipse(double RX01, double RY01, double ANG01_R, double RX02, double RY02, double posx, double posy, double my_x, double my_y) {
// STEP1 : E2を単位円にする変換をE1に施す
double DefAng = ANG01_R;
double Cos01 = cos(DefAng);
double Sin01 = sin(DefAng);
double nx = RX02*Cos01;
double ny = -RX02*Sin01;
double px = RY02*Sin01;
double py = RY02*Cos01;
double ox = cos(ANG01_R) * (my_x - posx) + sin(ANG01_R) * (my_y - posy);
double oy = -sin(ANG01_R) * (my_x - posx) + cos(ANG01_R) * (my_y - posy);
// STEP2 : 一般式A~Gの算出
double rx_pow2 = 1.0 / (RX01 * RX01);
double ry_pow2 = 1.0 / (RY01 * RY01);
double A = rx_pow2 * nx * nx + ry_pow2 * ny * ny;
double B = rx_pow2 * px * px + ry_pow2 * py * py;
double D = 2.0 * (rx_pow2 * nx * px + ry_pow2 * ny * py);
double E = 2.0 * (rx_pow2 * nx * ox + ry_pow2 * ny * oy);
double F = 2.0 * (rx_pow2 * px * ox + ry_pow2 * py * oy);
double G = ox * ox * rx_pow2 + oy * oy * ry_pow2 - 1.0;
// STEP3 : 平行移動量(h,k)及び回転角度θの算出
double tmp1 = D * D - 4.0 * A * B;
double h = (F * D - 2.0 * E * B) / tmp1;
double k = (E * D - 2.0 * A * F) / tmp1;
double Th = ((B - A) == 0) ? 0.0 : atan2(D, B - A) / 2.0;
// STEP4 : +1楕円を元に戻した式で当たり判定
double CosTh = cos(Th);
double SinTh = sin(Th);
double A_tt = CosTh * CosTh * A + SinTh * SinTh * B - SinTh * CosTh * D;
double B_tt = SinTh * SinTh * A + CosTh * CosTh * B + SinTh * CosTh * D;
double KK = A * h * h + B * k * k + D * h * k - E * h - F * k + G;
if (KK > 0.0) KK = 0.0;// 念のため
double Rx_tt = 1.0 + sqrt(-KK / A_tt);
double Ry_tt = 1.0 + sqrt(-KK / B_tt);
double x_tt = CosTh * h - SinTh * k;
double y_tt = SinTh * h + CosTh * k;
double JudgeValue = (x_tt * x_tt) / (Rx_tt * Rx_tt) + (y_tt * y_tt) / (Ry_tt * Ry_tt);
return (JudgeValue <= 1.0);
}
//DLLtest.h
#pragma once
#ifdef DLLTEST_EXPORTS
#define DLLTEST_API extern "C" __declspec(dllexport)
#else
#define DLLTEST_API extern "C" __declspec(dllimport)
#endif // DLLTEST_EXPORTS
DLLTEST_API int CollisionEllipse(double RX01, double RY01, double ANG01_R, double posx, double posy, double my_x, double my_y);
//DLLtest.hsp
#include "d3m.hsp"
#uselib "DLLtest.dll"
#cfunc CollisionEllipse_DLL "CollisionEllipse" double,double,double,double,double,double,double
#const angle M_PI/3
#module
#defcfunc CollisionEllipse double RX01,double RY01,double ANG01_R,int posx,int posy,double my_x,double my_y
// STEP1 : E2を単位円にする変換をE1に施す
DefAng = ANG01_R
Cos01 = cos(DefAng)
Sin01 = sin(DefAng)
nx = Cos01
ny = -Sin01
px = Sin01
py = Cos01
ox = cos(ANG01_R)*(my_x - posx) + sin(ANG01_R)*(my_y - posy)
oy = -sin(ANG01_R)*(my_x - posx) + cos(ANG01_R)*(my_y - posy)
// STEP2 : 一般式A~Gの算出
rx_pow2 = 1.0 / (RX01 * RX01)
ry_pow2 = 1.0 / (RY01 * RY01)
A = rx_pow2*nx*nx + ry_pow2*ny*ny
B = rx_pow2*px*px + ry_pow2*py*py
D = 2.0 * (rx_pow2*nx*px + ry_pow2*ny*py)
E = 2.0 * (rx_pow2*nx*ox + ry_pow2*ny*oy)
F = 2.0 * (rx_pow2*px*ox + ry_pow2*py*oy)
G = ox*ox*rx_pow2 + oy*oy*ry_pow2 - 1.0
// STEP3 : 平行移動量(h,k)及び回転角度θの算出
tmp1 = D*D - 4.0*A*B
h = (F*D - 2.0*E*B) / tmp1
k = (E*D - 2.0*A*F) / tmp1
if (B - A) == 0 {
Th = 0
}
else {
Th = atan(D, B - A) / 2.0
}
// STEP4 : +1楕円を元に戻した式で当たり判定
CosTh = cos(Th)
SinTh = sin(Th)
A_tt = CosTh*CosTh*A + SinTh*SinTh*B - SinTh*CosTh*D
B_tt = SinTh*SinTh*A + CosTh*CosTh*B + SinTh*CosTh*D
KK = A*h*h + B*k*k + D*h*k - E*h - F*k + G
if KK > 0.0 { ; // 念のため
KK = 0.0
}
Rx_tt = 1.0 + sqrt(-KK / A_tt)
Ry_tt = 1.0 + sqrt(-KK / B_tt)
x_tt = CosTh*h - SinTh*k
y_tt = SinTh*h + CosTh*k
JudgeValue = (x_tt * x_tt) / (Rx_tt * Rx_tt) + (y_tt * y_tt) / (Ry_tt * Ry_tt)
return (JudgeValue <= 1.0)
#defcfunc judge double d_x,double d_y,double my_x,double my_y,double r
tmpx = d_x-my_x
tmpy = d_y-my_y
tmpx *= tmpx
tmpy *= tmpy
return (r*r <= tmpx+tmpy)
#global
data = 0
//HSPで点と楕円の当たり判定
///データー1///////////////////////////////////////
flag = 0
repeat 100
begin_t = d3timer()
repeat 100000
flag = CollisionEllipse(400,300,angle,500,500,cnt\1000,cnt\1000)
loop
data += d3timer()-begin_t
loop
pos 0,0
logmes double(data)/100.0
///初期化//////////////////////////////////////////*/
data = 0
flag = 0
//DLL(C++)で点と楕円の当たり判定
///データー2///////////////////////////////////////
flag = 0
repeat 100
begin_t = d3timer()
repeat 100000
flag = CollisionEllipse_DLL(400,300,angle,500,500,cnt\1000,cnt\1000)
loop
data += d3timer()-begin_t
loop
pos 0,0
logmes double(data)/100.0
///初期化//////////////////////////////////////////
data = 0
flag = 0
//HSPで点と円の当たり判定(おまけ)
///データー3///////////////////////////////////////
flag = 0
repeat 100
begin_t = d3timer()
repeat 100000
flag = judge(500,500,cnt\1000,cnt\1000,300)
loop
data += d3timer()-begin_t
loop
pos 0,0
logmes double(data)/100.0
///初期化//////////////////////////////////////////
dialog "Done"
end
・実験結果
| HSPで点と楕円の当たり判定 | 484.230000ms |
|---|---|
| DLL(C++)で点と楕円の当たり判定 | 39.590000ms |
| HSPで点と円の当たり判定(おまけ) | 40.580000ms |
但し、DLLを使用するとオーバーヘッドが発生するので
DLLを使用するのは、HSPでは本当に遅くなる複雑な計算や
HSPではできないような特殊な計算をするときのみ使用してください。
HSPを諦めてC,C++,Jave,C#などを使いましょう。
HSPを卒業して他の言語に挑戦してみてください。
HSPが遅いと感じている時点であなたには相当の実力があります。
もちろん、今までHSPで学んだことはほかの言語にも応用が効きます。
ゲームを作りたいのならC,C++,Java,C#
 | ゲーム作りで学ぶJavaプログラミング入門 Java 7版 (SCC books) [ 工学研究社 ] 価格:2,420円 |
 | Unity C# ゲームプログラミング入門 2020対応 [ 掌田津耶乃 ] 価格:3,740円 |
アプリケーションを作りたいのなら
C,C++,Pythonを勉強するとよいでしょう。
 | 価格:2,860円 |
それでは、またいつか。